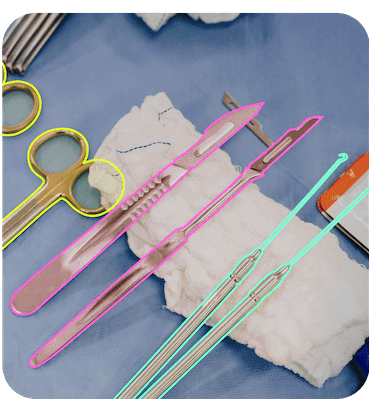
Computer Vision Models Power Advanced Applications
Computer vision uses algorithms to help cameras understand the real world.
There are four main types of models used in most computer vision applications.
Classification
Object Detection
Semantic Segmentation
Instant Segmentation
Classification
Classification is a process in computer vision and machine learning where an entire image, piece of text, or set of data is assigned to a specific category or label. For example, given a photo, a classification model might determine whether it contains a cat, dog, or bird. Unlike object detection, which identifies and locates multiple objects within an image, classification simply decides which single category the entire image or data belongs to, making it useful for tasks like sorting emails into “spam” or “not spam” or recognizing handwritten digits.
Object Detection
Object detection is a computer vision technique that identifies and locates specific objects within an image or video. Unlike simply classifying an entire image as containing a certain object (like a cat or a dog), object detection goes a step further by drawing a box around each detected object and labeling it. This allows the system to understand not only what objects are in the image but also where they are, which is essential for tasks like identifying pedestrians and other vehicles in autonomous driving or detecting items in a security camera feed.
Semantic Segmentation
Semantic segmentation is a computer vision technique that involves labeling every pixel in an image with a specific category, like identifying different objects in a picture. For example, in a photo of a street, the system would label each pixel as part of a car, road, building, or tree. This allows the entire scene to be broken down into meaningful parts, which can be useful in applications like self-driving cars, where the vehicle needs to recognize and understand everything around it to navigate safely.
Instant Segmentation
Instance segmentation is a computer vision technique that combines both object detection and semantic segmentation. It not only identifies and classifies each object in an image but also distinguishes between different instances of the same object. For example, if there are multiple cars in a photo, instance segmentation will label each one separately (e.g., “Car 1,” “Car 2”) and draw precise boundaries around each car. This technique is useful in applications like autonomous driving, where it’s important to recognize not just the type of objects but also the individual instances of those objects for better decision-making.
Key Points
Automated Image Recognition – Enables machines to automatically recognize and interpret visual data.
Real-Time Processing – Analyzes visual input in real-time, providing immediate insights and feedback.
High Accuracy – Delivers precise analysis, reducing errors in tasks like quality control, object detection, and facial recognition.
Scalable Solutions – Easily scalable to handle large datasets and high volumes of visual information.
Broad Applications – Used across various industries, including manufacturing, healthcare, automotive, and security.